R is a powerful and widely used programming language and software environment for statistical computing and data analysis. Developed by statisticians, R provides a vast array of tools for data manipulation, visualization, and modeling. Its open-source nature and extensive package ecosystem make it a popular choice among researchers, data scientists, and analysts. With its strong community support and integration capabilities, R is ideal for handling complex datasets, performing advanced statistical tests, and creating high-quality visualizations.
Installation and User Interface
Although extremely powerful, R has a terrible user interface and it is (highly) recommended to use a different GUI. Several options exist and, as I am writting this document, RStudio from Posit is one of the most popular (not my taste though). We will use it in this course.
Therefore the installation is a two steps procedure:
Watch this video to get a quick glimpse at the functionalities offered by the RStudio GUI.
The R language (well actually S ;-)
Disclaimer: You won’t learn how to do scientific programming with R in this course. Yet you will have to get a minimal knowledge. This is the aim of this section!
## Of course you could use R as a calculator but this is *NOT* scientific programming1+exp(2*sin(3.5* pi^2))
[1] 2.028197
## Create variables using either '<-' or '=' ('<-' is the historical assigment operator)a_string <-"zoo"a_number <-4.5a_vector <-c(1, 3, 5)##'c' might stand for concatenatea_repetitive_vector <-rep("a", 5)a_sequence <-3:5##integer between 3 and 5 *inclusive* (not like Python)a_matrix <-matrix(a_sequence, 2, 3)##a 2 x 3 matrix (note how recycling was used and how the matrix is populated by columns unless specified)
We see how to create character strings, vector, matrices… but other objects exist as well: namely data frame and lists. Data frames appear to be like a matrix but are more flexible than matrices since columns may be of different types, i.e., the 1st column contains real numbers while the 2nd character strings. This is not possible with matrices which makes data frames very appealing since data are likely to be of different kind.
## Create a data framedf <-data.frame(1:5, letters[1:5])df
X1.5 letters.1.5.
1 1 a
2 2 b
3 3 c
4 4 d
5 5 e
## Trying to force a matrix to be a data frame, look at what happensa_matrix
[,1] [,2] [,3]
[1,] 3 5 4
[2,] 4 3 5
a_matrix[1,1] <-"a"##setting the (1,1) element to be a charactera_matrix## oupppsss every entries have been converted to character strings !
[,1] [,2] [,3]
[1,] "a" "5" "4"
[2,] "4" "3" "5"
Lists are the most flexible objects (and again that come with a CPU cost). Roughly speeking, you can do whatever you want with list and it is like a data frame but now columns may have different sizes.
a_list <-list(a_matrix, a_string, df)
No that you know how to create object you may want to manipulate it.
## Access element of a vector/matrixa_vector[2]##the 2nd element, index starts à 1 not 0 like Python
[1] 3
a_matrix[2,1]##2nd row, 1st colum
[1] "4"
a_matrix[,1]##the 1st column
[1] "a" "4"
a_matrix[,-c(1, 3)]##the matrix without the 1st and 3rd columns
[1] "5" "3"
## For lists we have to use double bracketsa_list[[3]]##the 3rd component of the list, i.e, df
X1.5 letters.1.5.
1 1 a
2 2 b
3 3 c
4 4 d
5 5 e
a_list[[3]][1, 2]## the 1st row and 2nd column of df
[1] "a"
When doing scientific programming, having expression like a_list[1,2] is barely understandable. Similarly to the name you give to your objects/variables (or your child, bad joke I know), it is good practice to give sensible names to the columns / rows / components of a data frame / list.
## Creating a list with component names named_list <-list(name1 =1:4, name2 =rep("toto", 3))## Setting names to an 'unamed' listnames(a_list) <-c("toto", "tata", "tutu")## We can now access the component by its namea_list$toto## exactly the same as a_list[[1]]
[,1] [,2] [,3]
[1,] "a" "5" "4"
[2,] "4" "3" "5"
## For data frame we can use as before or using colnames (colnames works with matrix as well)colnames(df) <-c("var1", "var2")## We can do the same with rowsrownames(df) <-paste("row", 1:5)## Now we can access columns in two waysdf$var1##as for list
[1] 1 2 3 4 5
df[,"var1"]##new way, works for matrices as well
[1] 1 2 3 4 5
df["row 1",]##1st row selected from its name
var1 var2
row 1 1 a
We are all set to do some algebra!
A <-matrix(runif(16), 4)##4x4 matrix populated with random numbersx <-1:4##vector of size 41+ A##elementwise addition (add 1 to all entries)
R, as any high level language, has “vectorial” capabilities, i.e., can apply operations on vectors without using a loop. This is a bless and a curse. A curse because you write “math” that will give you a 0 on a exam (think about writing \(1 / A\) when \(A\) is a matrix :-( ). But a bless as you can code quite complex stuffs without any for/while loop (and get a fast code).
To sum up, R is high-level so you have to use its vectorial abilities otherwise just stick with low level languages as C.
a_grid <-seq(0, 2* pi, length =500)cos(a_grid)##evaluate cosinus on a grid
Alright we are ready to go a bit further to do scientific programming: writing our own functions, use for/while loops, if else statements and so on…
my_f <-function(arg1, arg2_with_default =1){## This function return the maximum (without using the builtin max function...)## function can output only one object so if needed output a listif (arg1 > arg2_with_default){ ans <- arg2_with_default } else##if only one line, curly brackets can be omitted ans <- arg2_with_defaultreturn(ans)}## A callmy_f(2, 3)##max(2, 3)
[1] 3
my_f(2)##max(2, 1)
[1] 1
my_f(arg2_with_default =5, 1)##max(1, 5)
[1] 5
For and while loops look like…(by the way never use a while loop if you know how many iterations you’ll do!)
for (i in1:100){print(i)}for (letter in LETTERS[1:5]){print(letter)}i <-10while (i >0){print(i) i <- i -1}
Graphics
As expected, R can do beautiful graphics including statistical ones such as boxplot, histogram. I cannot cover everything of course but let me tell you one thing. There are built in graphics using base R and, now a trendy way of doing plots that is based on the “grammar of graphics” way. The latter relies on the third party library ggplot2 that you need to install and load. Personnaly I am not very fond of ggplot because it is too verbose for my personnal taste, but people seem to like it so I have to mention it.
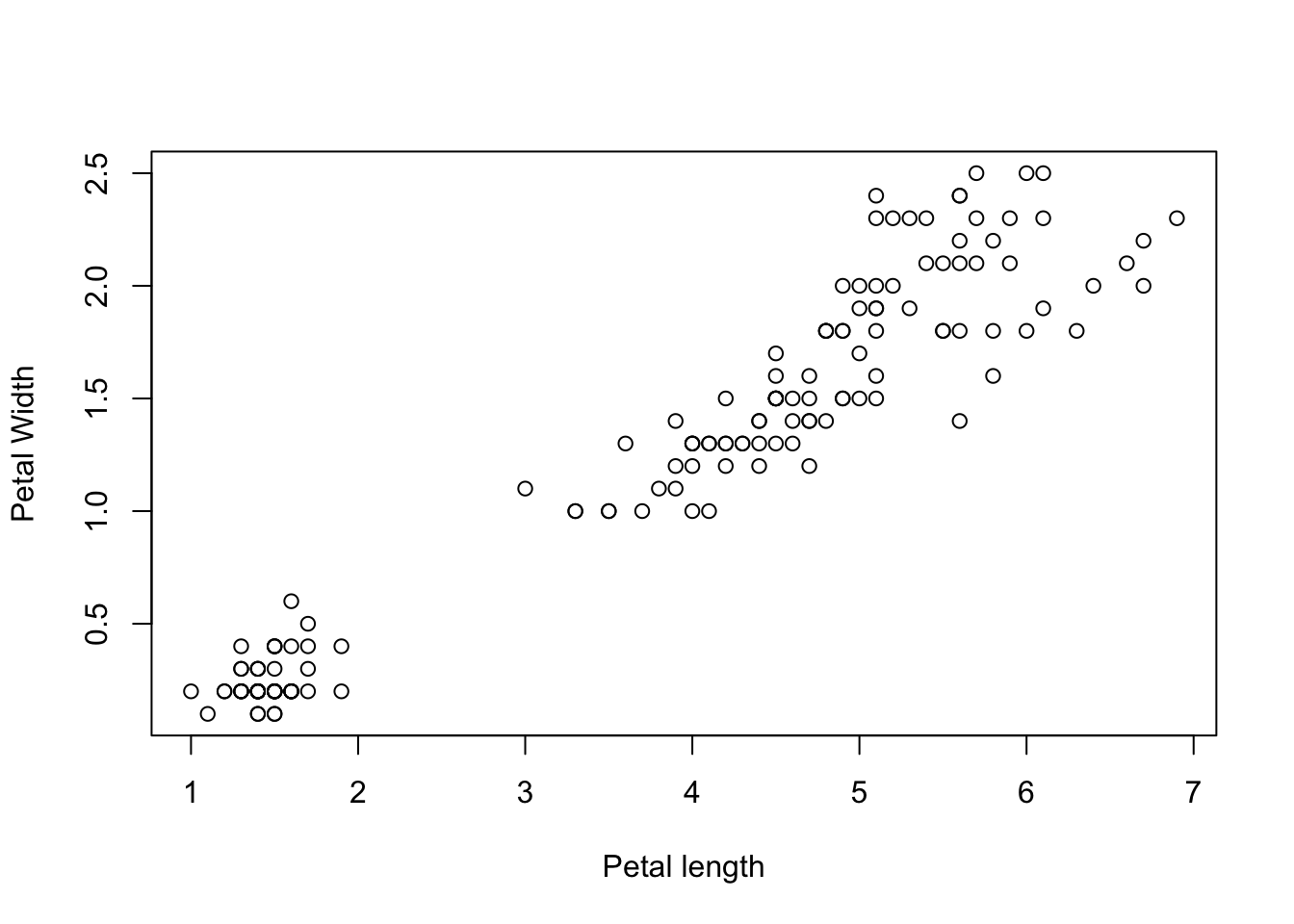
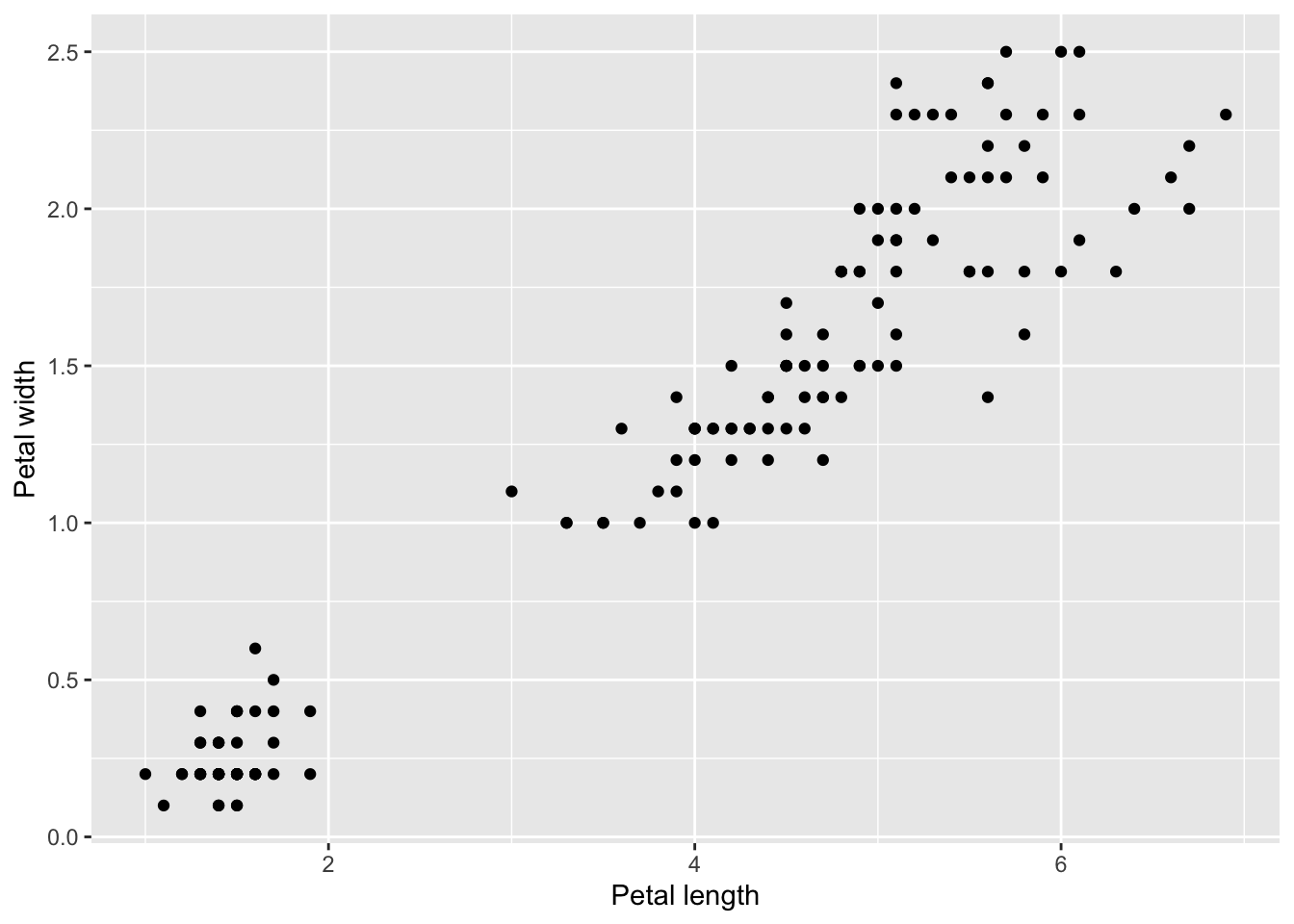
## ggplot way would belibrary(ggplot2)ggplot(iris) +geom_point(aes(Petal.Length, Petal.Width)) +labs(x ="Petal length", y ="Petal width")
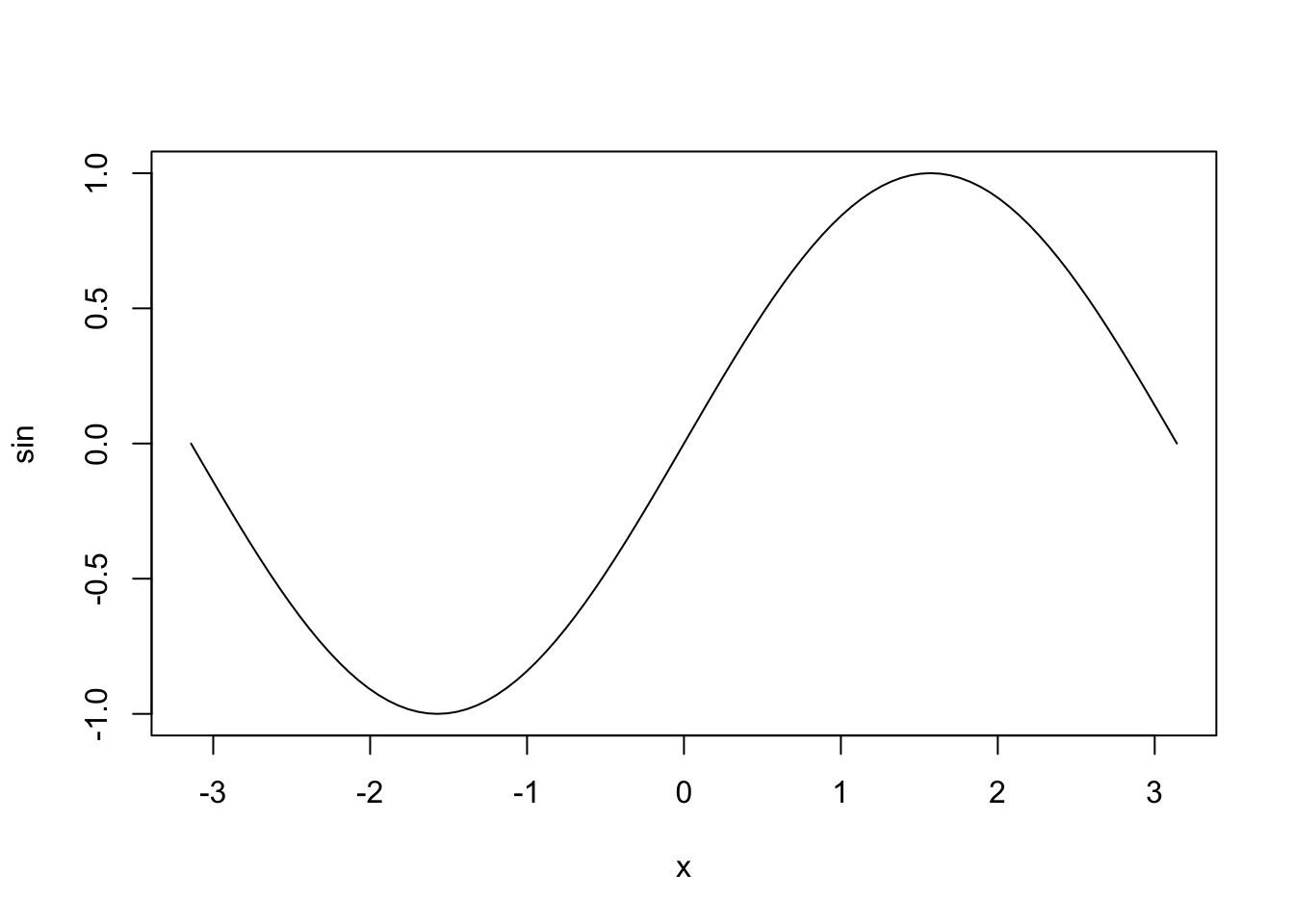
## We can plot a function without evaluating itplot(sin, from =-pi, to = pi)##Python why you don't have that--grrrrr
Of course, I won’t cover every possible plots but here are some just to tease you
boxplot(Sepal.Width ~ Species, data = iris)
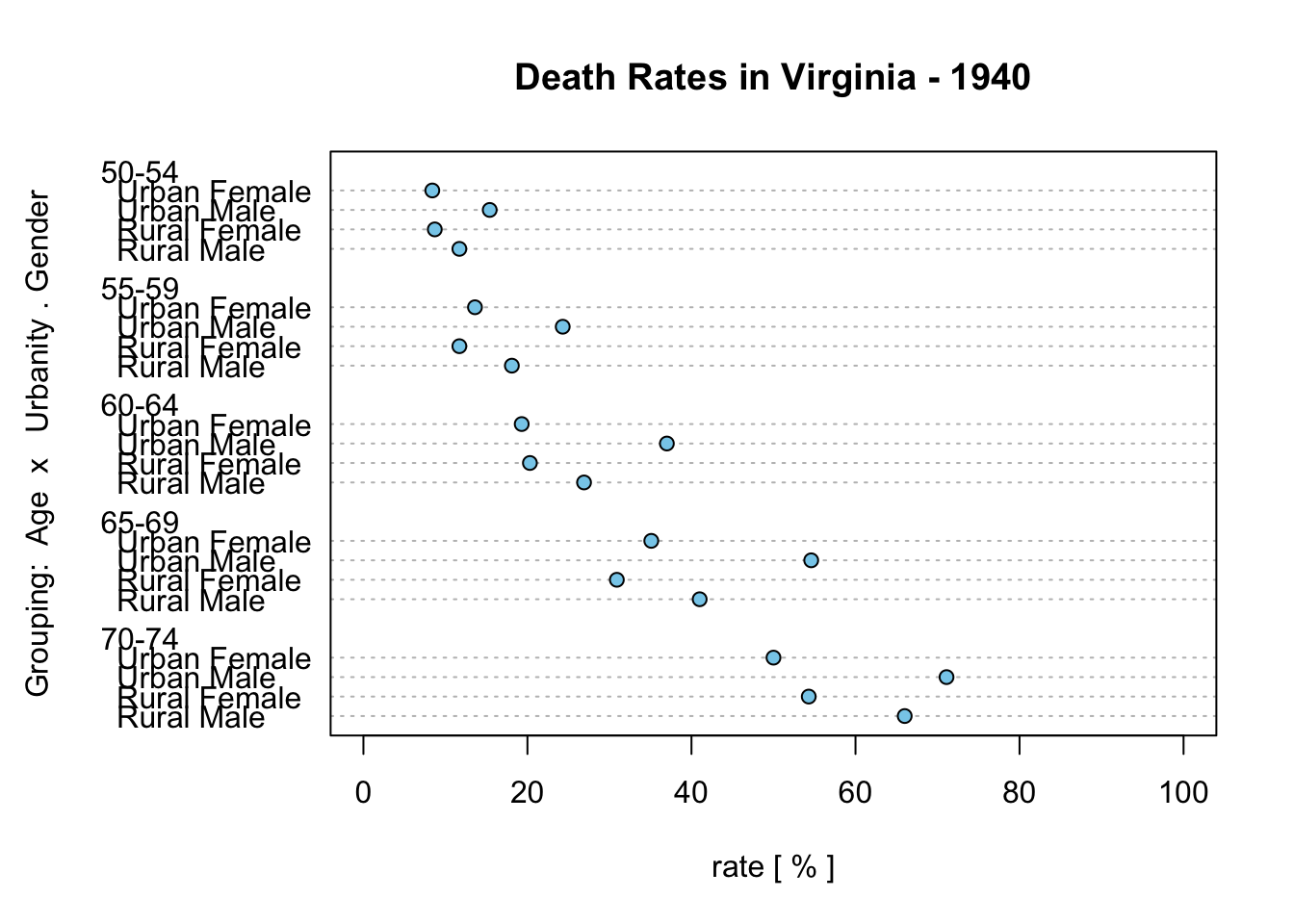
dotchart(t(VADeaths), xlim =c(0,100), bg ="skyblue",main ="Death Rates in Virginia - 1940", xlab ="rate [ % ]",ylab ="Grouping: Age x Urbanity . Gender")
qqnorm(precip)
The most important…
…is what you are going to learn in statistics and how R will help you apply it! And if you want to dive a bit further you may want to have a look at this (tidyverse oriented though).